Szerzők
A fejezet tartalma:
Nyelvek és nyelv
Univerzálékutatás és nyelvtípusok meghatározása
A nyelvek osztályozása
Minden mindennel összefügg
Sokan nehezen tudják elképzelni, hogy a világon kb. 7.000 különböző nyelv létezik. Ezek valóban mind „igazi nyelvek”? Nem lehet, hogy a többségük inkább valamely nyelv nyelvjárása (dialektusa)? Akik az európai nyelvi helyzetet ismerik, gyakran úgy gondolják, hogy az „igazi nyelv” mindig egy állam hivatalos nyelve, amelynek van írásos formája, írásbeli hagyománya és sztenderd változata, amelyet szótárak és nyelvtankönyvek írnak le, és az iskolában tanítanak. Ezért az európaiak úgy gondolhatják, hogy ha egy nyelv nem rendelkezik ezekkel a jellemzőkkel, akkor az „csak nyelvjárás”, és ezen gyakran azt is érthetik, hogy az ilyen nyelvek valahogy nem teljesek, és alsóbbrendűek pl. az angolhoz, a hollandhoz vagy a magyarhoz képest. Ez az európai felsőbbrendűségi érzés a 19. században egyértelműen megnyilvánult abban, hogy az Európán kívüli kultúrák nyelveit „primitív nyelveknek” bélyegezték. Ma már tudjuk, hogy nincs olyan, hogy „primitív nyelv”. Valójában a nyugati technikai fejlődéstől elzártan élő közösségek nyelvei sokszor igen összetett rendszerek, ezért is nagyon értékesek a nyelvészek számára.
Amikor valamely nyelvváltozatra azt mondjuk, hogy „csak” nyelvjárás, akkor nem gondoljuk egyenrangúnak a jobban ismert és sztenderd változattal vagy államnyelvi státusszal rendelkező nyelvvel. Ebből a nézőpontból azt gondolhatnánk, hogy például a kasub a lengyel nyelv egyik nyelvjárása, mert hasonlít a lengyelre, Lengyelországban pedig a lengyel a domináns nyelv. (Megjegyzendő, hogy ma a kasub nyelvet önálló nyelvnek ismerik el.) Hasonló az Oroszország Finnországgal határos területein beszélt karjalai és a finn nyelv viszonya. A „nyelv vagy nyelvjárás” kérdését ebben az esetben a két etnolektus (etnikai csoport által használt nyelvváltozat) közötti különbség fokának megállapításával lehet megválaszolni. Számos mai nyelvész szerint nem lehet egy-két kritérium alapján eldönteni, hogy bizonyos „lektusok” (dialektusok, etnolektusok) egyazon nyelvhez tartoznak-e vagy sem. Ennek megállapításához a kölcsönös érthetőségen vagy a különbség mértékén kívül számos egyéb tényezőt kell figyelembe venni. Ezért nehéz megállapítani azt is, hány nyelvet beszélnek ma a világon. Az azonban bizonyos, hogy több ezer olyan nyelv létezik, amelyek legalább annyira különböznek egymástól, mint az angol és a német.
NYELVEK ÉS NYELV
Mennyire különböznek egymástól a világ nyelvei? – e kérdésre a választ kereshetjük például a nyelvtanok különbözőségeiben.
A világon eltérő hagyományok alakultak ki a nyelvi struktúrák, szavak, mondatok vagy hangok tulajdonságainak leírására, így beszélhetünk például a nyelv leírásának európai, indiai és arab hagyományairól. Ezek egy vagy két nyelv elemzéséből nőttek ki, amelyek többnyire az irodalmi nyelvváltozatot (szent szövegek nyelvét vagy elismert írók műveit) vették alapul. Az európai nyelvtanírás alapjait a görög grammatikusok fektették le, majd az (írott) latinra alkalmazták és fejlesztették tovább. A kora középkortól ezt a „latin grammatikát” mintaként kezdték használni a többi európai, majd később a nem európai nyelvek (pl. a Spanyolország által meghódított amerikai területek őshonos nyelvei) leírására is. Azonban minél nagyobb mértékben különbözött az adott nyelv a latintól, annál kevésbé volt alkalmas ez a módszer a leírására. A latinból ismert kategóriákat és szerkezeteket minden nyelvben megtalálni vélték, a latintól eltérőeket azonban gyakran figyelmen kívül hagyták. Jó példa ez arra a bölcs mondásra, miszerint az ember csak azt találja meg, amit keres. Például az angolt úgy írták le, mintha lenne benne ablativus/határozói eset („of the book”) és vocativus/megszólító eset („Oh Lord!”), ugyanakkor egyáltalán nem vettek tudomást a határozott és határozatlan névelőkről (mivel a latinban nincsenek névelők). A századok során a latin grammatikán alapuló tradíció lassanként módosult, mert adaptálták a modern európai nyelvek leírására. Az európai nemzeti nyelveknek fokozatosan kialakult a saját nyelvleírási hagyományuk, mindazonáltal a latin grammatikaírási tradíció még mindig hatással van rájuk.
Az európai hagyománynak komoly kihívással kellett szembenéznie a 20. században, amikor az egyesült államokbeli antropológusok és nyelvészek érdeklődni kezdtek az amerikai őshonos nyelvek iránt, és úgy találták, hogy az európai nyelvtan nem alkalmas a leírásukra.
Mindez a nyelvleírás új módszereinek kidolgozására ösztönözte a nyelvészeket, ugyanakkor pedig a célok és alapelvek új értelmezését, azaz a nyelvtan új megközelítését váltotta ki. Az új nézőpont szerint a nyelvleírás (pl. egy nyelvtan) feladata, hogy objektív módon leírja, milyen formákat és szerkezeteket használnak egy nyelv beszélői.

A Tillohash-család. A családfő Benjamin Lee Whorf nyelvész adatközlője volt, akinek segítségével Whorf leírta a déli paiute nyelvet.
(A mű 1930-ban jelent meg.)
http://en.wikipedia.org/wiki/File:Tilohash.jpg
A modern nyelvtipológiai kutatások – így a WALS atlasz feldolgozásai – mögött is olyan módszerek állnak, amelyek a nyelvekben fellelhető sokféleséget rendszerezik. Következésképp elméletileg minden nyelvi struktúra leírására alkalmasak, bármely nyelvre alkalmazhatók. Ezt például a nyelvek beszédhangjainak leírásában figyelhetjük meg. A 19. század végén kidolgozott nemzetközi fonetikai ábécé (International Phonetic Alphabet: IPA) olyan jelrendszer, amely az eddig ismert összes emberi nyelv összes beszédhangjának leírására alkalmas. (Ezekkel a jelekkel találkozhatunk például az angol szótárakban is a szögletes zárójelbe tett alakok esetében; pl. apple [æpl]). Ehhez az alapot az az „eszköz” adja, amellyel az ember a hangokat képezi, mivel ez minden emberben azonos (a garat, a szájüreg, a nyelv, az ajkak). Ugyanakkor az IPA nem tartalmazna jeleket például a csettintő hangok jelölésére, ha nem ismernénk például a khoisza nyelvet.
Egyesek lényegében azonosnak fogják fel az összes nyelvet, amit azzal indokolnak, hogy valamennyit az emberi tudat hozta létre, ezért a különböző nyelvek tulajdonképpen egyazon emberi képesség, a nyelv megtestesülései. A gyerekek az egész világon nagyjából ugyanannyi idő alatt tanulják meg az anyanyelvüket, ami azt mutatja, hogy az anyanyelvi beszélők szempontjából nézve nincsenek „nehéz” és „könnyű” nyelvek. Egyes nyelvészek szerint a gyerekek pusztán a hallott nyelv (input) alapján nem lennének képesek megtanulni az anyanyelvüket, tehát birtokukban kell lennie valamilyen velük született általános nyelvi szabálykészletnek, amelynek segítségével képesek a környezetük nyelvének vagy nyelveinek rendszerét reprodukálni. Ezt a szabálykészletet univerzális grammatikának nevezték el. Az univerzális grammatika szabályai határozzák meg, milyen struktúrák lehetségesek az egyes nyelvekben. Vannak olyan nézetek, amelyek szerint a nyelvészet célja az absztrakt univerzális grammatika feltárása, nem pedig a ténylegesen beszélt különböző nyelvek leírása. Legszélsőségesebb megfogalmazásuk azt állítja, elég egyetlen nyelvet alaposan tanulmányozni, a többi nyelvvel való összehasonlítást csak a hipotézisek ellenőrzésére kell bevetni.
Más nyelvészek szerint minden nyelv egyedi rendszer, amelyet önmagáért kell tanulmányozni és leírni. Egy vagy két nyelv szabályszerűségei alapján nem lehet a nyelvre vonatkozó általánosításokat vagy következtetéseket levonni – de még száz alapján sem. A nyelv mint emberi képesség feltérképezéséhez elméletileg minden beszélt vagy valaha beszélt emberi nyelvet ismernünk kellene. Mivel azonban ez nem lehetséges, nem tudjuk megmondani, mely struktúrák fordulhatnak elő az emberi nyelvekben, és melyek nem. Az európai és az amerikai nyelvészeti kutatásokat a harmincas és ötvenes évek között meghatározó, strukturalizmusnak nevezett irányzat alapvetésként fogadta el, hogy minden nyelvnek saját külön rendszere van, amelyet önmagában kell vizsgálni anélkül, hogy más nyelvekre vonatkozó ismereteink alapján próbálnánk következtetéseket levonni.
Ma a legtöbb nyelvész valószínűleg valahol a két szélsőséges nézet („lényegében az összes nyelv azonos, tehát elég csak egyet tanulmányozni”, illetve „lényegében minden nyelv különböző, és nem lehet általánosításokat megfogalmazni”) között foglalna állást. A nyelvek igen eltérőek, de azért találunk bennük hasonló struktúrákat és nyelvtani kategóriákat. A még le nem írt nyelvek tanulmányozásával bukkanhatunk eddig ismeretlen újdonságokra, és minden bizonnyal találunk olyan szabályszerűségeket is, amelyek a világ más nyelveiben is léteznek.
UNIVERZÁLÉKUTATÁS ÉS NYELVTÍPUSOK MEGHATÁROZÁSA
A valamennyi nyelvre érvényes, közös jellemzőket nyelvi univerzáléknak hívjuk. Az univerzálék tanulmányozásának és értelmezésének különböző irányzatai vannak. A fent említett „univerzális grammatika” fogalmán alapuló irányzat szerint az univerzálék a tényleges nyelvi struktúrák mögött (a nyelv mélystruktúrájában) meghúzódó absztrakt szabályok. Ez az irányzat tehát feltételezi például az [igeidő] mint absztrakt jegy létezését. Az alábbi táblázat azt mutatja, hogy az [igeidő] jegy hányféleképpen valósulhat meg például az angolban és a magyarban:
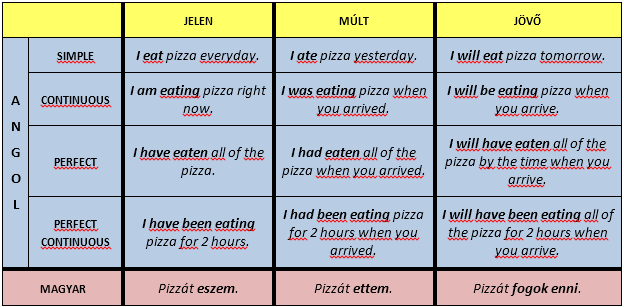
Az abszolút univerzálék (valamennyi nyelvre érvényes állítások) többnyire nagyon általánosak, például: „minden nyelvnek vannak eszközei egy állítás tagadására” vagy „minden beszélt nyelvben vannak magánhangzók és mássalhangzók”. Nincs túl sok olyan általános állítás, amely valóban a világ összes nyelvére igaz. Vannak, akik vitatják például azt is, hogy minden nyelvben jól elkülöníthető, külön szófajnak tekinthetők a főnevek és az igék. Amit az egyik nyelvben igének hívnak, nagyon különbözhet egy másik nyelv igefogalmától. Wolfgang Klein nyelvész szerint az „ige” kifejezést alkalmazni olyan különböző jelenségekre, mint a latin nyelv igéi és a kínai nyelv igéi olyan, mintha ugyanazt a kifejezést használnánk a rizsre és a burgonyára, és a rizst a kínaiak burgonyájának hívnánk (Klein 1995: 81).
Az Interaktív térképen az iwaidja nyelv második és a hoocąk/vinebégó nyelv harmadik feladatában találhatsz példákat arra, hogy a szófajok miképpen térnek el az európai nyelvek szófajaitól.
Az univerzálék másik típusát implikációs univerzáléknak nevezzük. Ezek a következő formában fogalmazhatók meg: „Ha egy nyelvben létezik A jegy, akkor biztos, hogy B jegy is létezik”. Például: „Ha egy nyelvben van kettes szám [A jegy], akkor többes szám [B jegy] is van” – ez azt jelenti, hogy nincs olyan nyelv, amely jelölné például a főnevek kettes számát, a többes számát viszont nem. Vannak tehát olyan nyelvek, amelyek a kettes és többes számot is jelölik. Az állítás nem jelenti azt, hogy minden nyelvben létezik az [A jegy], példánkban: hogy minden nyelv jelöli a főnevek kettes számát. Az implikációs univerzálék kutatása az emberi gondolkodás ilyenfajta szabályszerűségeire is fényt derít. Érdemes megjegyezni, hogy a kettes szám nem csak távoli, egzotikus nyelvekben fordul elő. Az indoeurópai nyelvek közül néhány őrizte meg csupán, ezek egyike a szlovén. A mesec ’hónap’ jelentésű szó kettes száma meseca, többes száma pedig meseci. Az uráli nyelvek közül például a hantiban, a manysiban, a számiban és a szamojéd nyelvekben is van kettes szám.
Az abszolút univerzálékon kívül a nyelvészek olyan tulajdonságokat is vizsgálnak, amelyek jellemzők a nyelvek nagy többségére, de nem fordulnak elő az összesben. Ezeket statisztikai univerzáléknak vagy szerencsésebb kifejezéssel univerzális tendenciáknak is hívják. Például a nyelvek többségében az alany helye a mondatban előbb van, mint a tárgyé. Az implikációs univerzálék többsége is inkább tendencia, mint abszolút univerzálé.
A nyelvek tulajdonságainak kutatása katalogizálással és a különbségek rendszerezésével történik. Ezzel foglalkozik a nyelvtipológia tudománya. A nyelvtipológia egyebek között – hogy a fenti példához kapcsolódjunk – kiinduló kérdésként azt teszi fel, hogy miként jelölik a világ nyelvei a szám kategóriáját. Az eredmények alapján a következő nyelvtípusok között tesz különbséget: 1. a számot nem jelölő nyelvek, 2. az egyes számot és többes számot jelölő nyelvek, 3. az egyes számot, többes számot és kettes számot (stb.) megkülönböztető nyelvek. Vannak olyan nyelvtipológiai kutatások is, amelyek egy egyszerű eldöntendő kérdéssel indulnak: „Jelöli-e (azaz formálisan megkülönbözteti-e) egy bizonyos nyelv a múlt időt?” A válaszok alapján a nyelveket két csoportra osztják. A következő lépésben az „igen”-nel válaszoló csoport nyelveit tovább vizsgálják, például azt keresik, hogy a múlt időt formailag jelölő nyelvek esetében milyen további kategóriák állapíthatók meg a múltra vonatkozóan. Egyes nyelvek például különbséget tesznek a beszéd pillanatához képest közelebbi és távolabbi múlt között. Az Amazóniában beszélt yagua nyelv különlegessége, hogy a beszéd pillanatától való időbeli távolságnak öt fokozatát tudja kifejezni: ‘pár órája’, ‘egy napja’, ‘kb. egy hete, de legfeljebb egy hónapja’, ‘több mint egy hónapja, de legfeljebb két éve’ és ‘valamikor régen’. Ezeket a múlt időket különbözőképpen jelölik (l. még Dahl & Velupillai 2011).
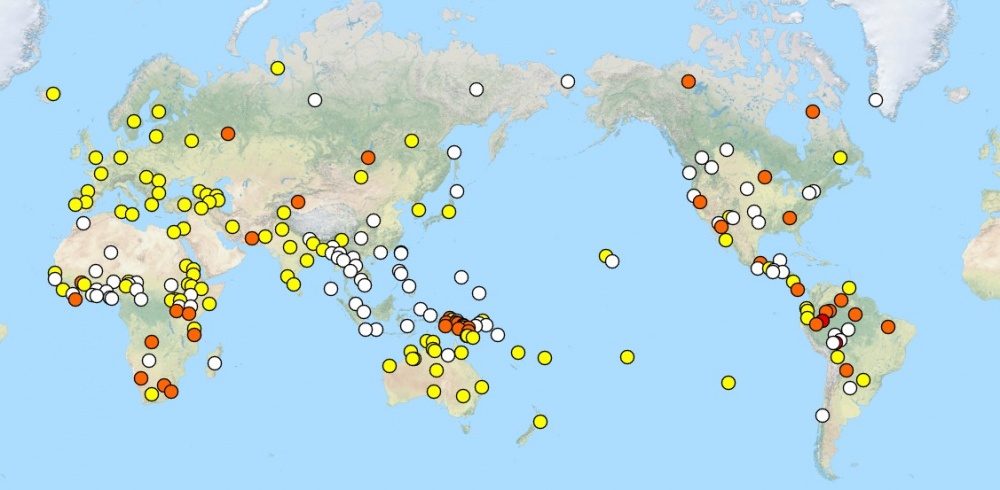
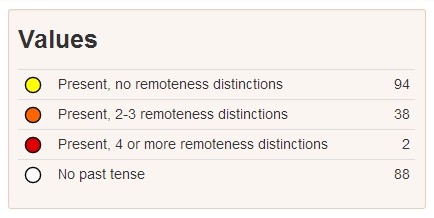
http://wals.info/feature/66A#2/29.8/162.9
Amint látható, bizonyos nyelvi tulajdonságok és nyelvtípusok gyakoribbak a világ egyes részein, mint másokon. A The World Atlas of Language Structures (WALS) online atlasz összesen 2.679 nyelvben 144 különböző nyelvi tulajdonságot tárgyal (nem minden jegyet vizsgáltak meg minden nyelvben), és bemutatja földrajzi eloszlásukat (Dryer & Haspelmath 2011). Az adatbázisban szereplő nyelvi tulajdonságok skálája nagyon széles, például a következő kérdésekre kaphatunk választ:
„Mely nyelvekben fordulnak elő nazális magánhangzók?”;
„Hol vannak a világon tonális nyelvek?”,
„Mely nyelvek használják ugyanazt a szót a ‘kéz’ és a ’kar’ megnevezésére?”;
„Mely nyelvben honnan származik a ’tea’ szó?” .
A NYELVEK OSZTÁLYOZÁSA
A nyelvek különböző szempontok szerint csoportosíthatók. A genetikus osztályozás (nyelvcsaládok vagy eredet szerinti osztályozás) alapvetése, hogy az egy családba tartozó nyelvek egy közös alapnyelvre vezethetők vissza. A nyelvcsaládokon belül alnyelvcsaládokat különböztetünk meg, amelyeket tovább oszthatunk csoportokra, alcsoportokra és még kisebb egységekre. Például az Európában beszélt nyelvek többsége az indoeurópai nyelvcsaládba tartozik, és az indoeurópai alapnyelvből alakult ki. Az indoeurópai nyelvcsalád számos csoportra osztható. Ilyen például az újlatin, a germán, a balti és a szláv nyelvek csoportja. Az utóbbiba olyan nyelvek tartoznak, mint a lengyel, az ukrán, az orosz, a horvát, a szlovén, a szerb, illetve a kisebbek közül az alsószorb, a macedón. Ezek a nyelvek mind a szláv alapnyelvből alakultak ki.
Előfordul az is, hogy egy nyelvcsaládhoz vagy nyelvcsaládon belüli csoporthoz tartozó nyelvek osztályozására egymás mellett létező különböző szempontok vannak, mint például a bantu nyelvek esetében, amelyeket csoportosítottak már földrajzi kritériumok és a nyelvtani rendszer eltérései szerint is, a nyelvtörténeti részletek tisztázása pedig még ma is folyik.
A nyelvcsaládokról a Britannica Online Encyclopedia oldalán is olvashattok.
A következő linkre kattintva a dravida nyelvekről tudhattok meg többet:
http://www.britannica.com/EBchecked/topic/171083/Dravidian-languages
Itt pedig az ausztronéz nyelvcsaládról tudhattok meg többet:
http://www.britannica.com/EBchecked/topic/44563/Austronesian-languages
Az alábbi linken az uráli nyelvekről tájékozódhattok:
http://www.britannica.com/EBchecked/topic/619069/Uralic-languages
Az uráli alapnyelv rekonstruált szavait itt találod:
http://www.uralonet.nytud.hu/
MINDEN MINDENNEL ÖSSZEFÜGG
A nyelvekben fellelhető hasonlóságokat ritkábban magyarázhatjuk nyelvrokonsággal, sokkal gyakoribbak a tipológiai okok. E hasonlóságok a hangok, a szavak és a mondatok szintjén is jelentkeznek. A szavak szintjén jelentkező hasonlóságok ugyanakkor összefügghetnek a hangok vagy a mondatok szintjén jelentkező hasonlóságokkal. A továbbiakban mindezekre a szó kategóriájára hivatkozva fogunk rámutatni.
Ha megkérdezzük valakitől azt, hogy mi is a szó, akkor biztosan nem fog tudni mondani egy általános, minden nyelvre érvényes meghatározást. Mivel a nyelvek különféle hangtani, alaktani, mondattani szerkezeteket valósítanak meg, a szó fogalmát is csak nyelvenként lehet meghatározni — hangtani, jelentéstani, alaktani és mondattani szempontok alapján. Egyszerű azt mondanunk, hogy a modern alfabetikus írással írt szövegekben a szó olyan betűsor, amelyet más betűsoroktól szóköz vagy írásjel választ el, holott valójában a kérdés jóval összetettebb.
A nyelveket csoportosítani lehet aszerint, hogy egy szóalak hány morfémát tartalmazhat, amely alapján a nyelveket egy skálán tudjuk elhelyezni. Ez egyben jelzi azt is, hogy nem élesen elkülönülő csoporthatárokról van szó. A skála egyik végén az analitikus nyelvek állnak, ahol egy szó egy morfémából áll, a másik végén pedig a poliszintetikus nyelvek. Ezekben egyetlen szó számos morfémát tartalmazhat, ami gyakorlatilag mondatértékűvé teszi.
analitikus >>> szintetikus >>> poliszintetikus
(szó = morféma) (szó > morféma) (szó = mondat)
A szintézis fokát jól mutatja, ha megnézzük, hogy egy szóalak átlagosan hány morfémát (tő, rag, képző stb.) tartalmaz (Haspelmath – Sims 2010: 6, Greenberg 1959 alapján):
grönlandi inuit 3.72
szanszkrit 2.59
szuahéli 2.55
óangol 2.12
német 1.92
modern angol 1.68
vietnámi 1.06
Az említett nyelvek közül a grönlandi a legnagyobb mértékben szintetizáló, átlagosan majdnem négy morfémát tartalmaz egy szó, a vietnámi pedig a leganalitikusabb, amely leginkább megvalósítja az izoláló típust: az egy szóalakra jutó morfémaszám alig haladja meg az egyet.
Különböző hosszúságú és műfajú szövegek alapján végezzetek számítást arról, a magyar szavak átlagosan hány morfémából állnak!
A fenti listából az is kiderül, hogy a szintetizálás mértéke egy adott nyelven belül az idők folyamán változhat. Az angol nyelv esetében jól látható, hogy egyre kevésbé szintetizáló, egyszerűsödik a morfológiája (azaz egyre kevesebb a toldalékok száma), így az egy szóban megjelenő morfémák átlagos száma jelentősen csökkent.
Nézzük meg a ‘Ha megvársz, akkor elmegyek veled.’ jelentésű mondatot egy analitikus és egy poliszintetikus nyelvben! (Eifring – Theil 2005)
analitikus (izoláló nyelv): kínai
nǐ děng wǒ, wǒ jiù gēn nǐ qù.
E/2 vár E/1 E/1 akkor -val/-vel E/2 megy
szintetizáló: inuktitut (kanadai eszkimó nyelv)
Utaqqiguvinga, aullaqatiginiaqpagit.
‘Ha megvársz, akkor biztosan elmegyek veled.’
Utaqqi-gu- vi- nga, aulla- qati- gi- niaq- pa- git
vár ha E/2 E/1 megy társ POSS FUT ASS E/1-E/2
(POSS = birtokol, FUT = jövő idő, ASS = asszertív, ami kb. úgy fordítható, hogy ’bizonyosan’, a beszélő határozott, biztos abban, hogy meg fogja tenni azt, amit állít.)
Kitűnik, hogy ugyanazt a tartalmat a kínai nyolc szóalakkal, az inuktitut mindössze kettővel fejezi ki.

http://www.aec-cea.ca/2013/05/nunavuts-main-language-officially-recognized.html
Alább ugyanannak a szövegnek grönlandi inuit és angol fordítása található (forrás: http://www.inuit.org/). Figyeljük meg, hogy az inuit mennyivel terjedelmesebb, a szavak hosszabbak. Az angol verzió esetében soronként 7-10 szó fér el, az inuit esetében csak 3-5.


Ez pedig egy kínai szöveg pinyin (latin betűs) átírásban (http://www.csulb.edu/~txie/202/PINYIN1.PDF):

Látható, hogy rövid szóalakok szerepelnek a szövegben, s alig van olyan, amelyik két vagy több szótagból áll.
Az analitikus nyelveket nevezik izolálóknak is. Az ilyen nyelvek kevésbé élnek alaktani eszközökkel (toldalékokkal vagy hajlítással, vö. német Bruder ’fiútestvér’ ~ Brüder ’fiútestvérek’). Ezek helyett hangtani, lexikai vagy mondattani eszközöket használnak. Ez utóbbiak közül a legfontosabb talán a szórend, azaz a mondatrészek sorrendjének is van jelentés-megkülönböztető szerepe. (L. pl. a következő angol mondatpárt: The dog bites the postman, ill. The postman bites the dog.) Ebből az is következik, hogy az ilyen nyelvekben egyfelől a szórend kötöttebb, másfelől ugyanannak az elemnek (szónak) lehet lexikai és grammatikai jelentése is. Ilyenek például a személyjelölő elemeknek: a fenti kínai mondatban nehéz meghatározni, hogy a személyjelölők névmások, grammatikai elemek (pl. birtokviszony kifejezésére szolgálnak), vagy valamely más kategória tagjai.
Ha egy nyelvben jellemzően rövid, többnyire egy szótagból álló szavak vannak, akkor bennük a hangok korlátozott kombinálódási lehetősége miatt a létrehozható szavak száma is alacsony. Ilyenkor a tónusok különböztetik meg az egyébként azonos hangalakú szavakat. A tonalitás jellemzően, de nem kizárólag az analitikus (izoláló) nyelvek eszköze.
A szintetikus nyelvek egyik csoportját az agglutináló nyelvek alkotják. Ezekben a nyelvekben egyetlen morfémának több funkciója lehet, mint például a magyarban a -nak/-nek ragnak (pl. A fiúnak dobtam a labdát. Marinak három macskája van.) Előfordul azonban az is, jóllehet ritkábban, hogy egy morfémához egyetlen funkció kötődik. Erre példaként leggyakrabban a török nyelvet szokták említeni, amelyben a többes szám jele csak a többes számot fejezi ki: ev ‘ház’, ev-ler ‘házak’. A magyarban az igeragozás –m ragja utal a cselekvő személyére, számára, valamint a tárgy határozottságára is.
Grammatikai funkciókat azonban más eszközökkel is ki tudnak fejezni a szintetizáló nyelvek, például úgy, hogy a grammatikai jelentést a tőben történő változás hordozza. Ezt hívjuk fúziónak.
A poliszintetikus nyelvek nemcsak funkcionális elemeket kapcsolnak a tövekhez, hanem akár több tőelem is szerepelhet egy szóalakban. Ennek leggyakoribb esete, amikor egy ige “bekebelezi” a tárgyát. Ezért a poliszintézist nevezik belső mondattannak is, hiszen egy-egy szóalakon belül szintaktikai viszonyok is megvalósulnak.
A szintetizálás mértékét az is mutathatja, hogy hány elemet tud a nyelv egy szóba belesűríteni, és ezek közül mennyinek van lexikális jelentése (azaz olyan, amit a szótárba is felvennénk). A szibériai nyivhben ez a szám akár öt is lehet.
pəi-mu-meń-vo-ńivx
repül-csónak-kormánylapát-fog-ember
’repülő csónak (= repülőgép) kormányát fogó ember’ = ’pilóta’
pəi-urla-ləx
repül-jó-időjárás
‘jó időjárás repüléshez’
Egy szerkezet összetettségét az is befolyásolja, hogy mely nyelvtani kategóriákat kötelező kifejezni az adott nyelvben. A magyar beszélő számára például természetes, hogy formailag megkülönböztetjük az egyes és a többes számot, amit általában toldalékkal fejezünk ki (ház – házak). Talán meglepő, de vannak olyan nyelvek, amelyek nem különböztetik meg formailag az egyes és többes számot. Vannak olyanok is, amelyek önálló lexikális elemeket, ún. funkciószavakat alkalmaznak, pl. tagalog bato ‘kő’, mga bato ‘kövek’. Sok nyelv, így a magyar és a török is, toldalékot használ: török ev ‘ház’, ev-ler ‘házak’. Ugyanakkor nem minden ragozó nyelv toldalékol a jobb oldalon, azaz nem a szó után teszi a toldalékot, hanem elé (pl. szuahéli m-toto ‘gyerek’, wa-toto ‘gyerekek’) vagy köré. A többes számot tőbeli hangváltozással is ki lehet fejezni: angol man, men. Az angol példa azt is megmutatja, hogy ugyanannak a kategóriának a kifejezésére (jelen esetben a többes szám) egy nyelvben többféle eszköz is előfordulhat. A tőbéli hang módosulása mellett ugyebár az angolban az -s toldalék is erre szolgál, de egy lexémának általában csak egy “helyes” alakja lehet, így a *mans, *womans, *childs alakok nem jók. Más nyelvekben reduplikációt találunk, például a malájban: anak ‘gyerek’, anak-anak ’gyerekek’. Mint látható, a reduplikáció ugyanúgy formai (alaktani) eljárás, mint a toldalékolás, de a reduplikáció esetében mindig más forma fejezi ki az adott funkciót: az adott lexéma (szó) teljesen vagy részlegesen ismétlődő alakja.
Vannak olyan nyelvek, amelyek toldalékokkal fejeznek ki olyan jelentéstartalmat, amelyet mások lexikai (szavakkal) vagy mondattani eszközökkel. Ilyen például annak jelzése, hogy az adott információhoz milyen forrásból jutott a beszélő (ezt a nyelvészetben evidencialitásnak nevezik). Például a nganaszanban külön toldalék jelzi az igén, ha a beszélő
- látta, hallotta, közvetlenül érzékelte az eseményeket,
- nem látta, de érzékelte (hallás, tapintás, szaglás útján) az eseményeket,
- valaki mástól hallott az eseményről,
- a beszélő a körülményekből következtetett arra, hogy az esemény bekövetkezett, be fog következni. (Lásd az interaktív térkép feladatát!)
Egy nganaszan nem teheti meg, hogy ezeket a körülményeket nem jelzi, elhallgatja. Ha egy magyar beszélő fontosnak tartja a forrás megjelölését, akkor ez körülírással, általában külön tagmondattal történik, például a 2. pontban ’Úgy hallom/úgy érzem, hogy…’, a 3.-ban ’Azt beszélik, hogy…’, a 4.-ben pedig a ’Szerintem…’ lehet ilyen elem a mondatban.

http://www.legacyofhope.ca/projects/bridging-our-communities/toolkit-inuktitut